Scalable Machine Learning with PySpark MLlib
Scalable Machine Learning with PySpark MLlib
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 1h 9m | 260 MB
Instructor: Warner Chaves
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 1h 9m | 260 MB
Instructor: Warner Chaves
In this course, you’ll learn how to build scalable ML pipelines, perform large-scale feature engineering, and train models on massive datasets.
What you'll learn
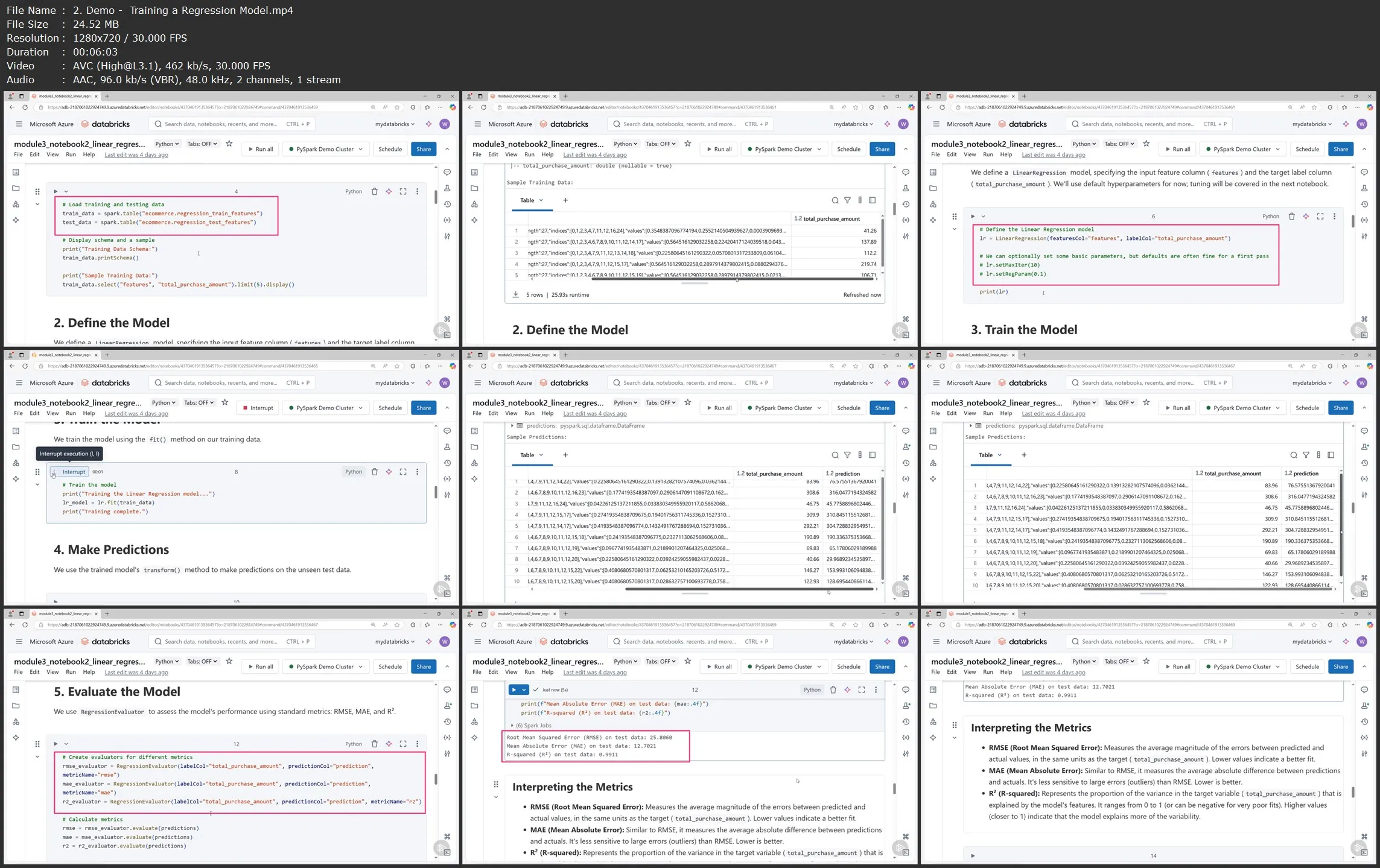
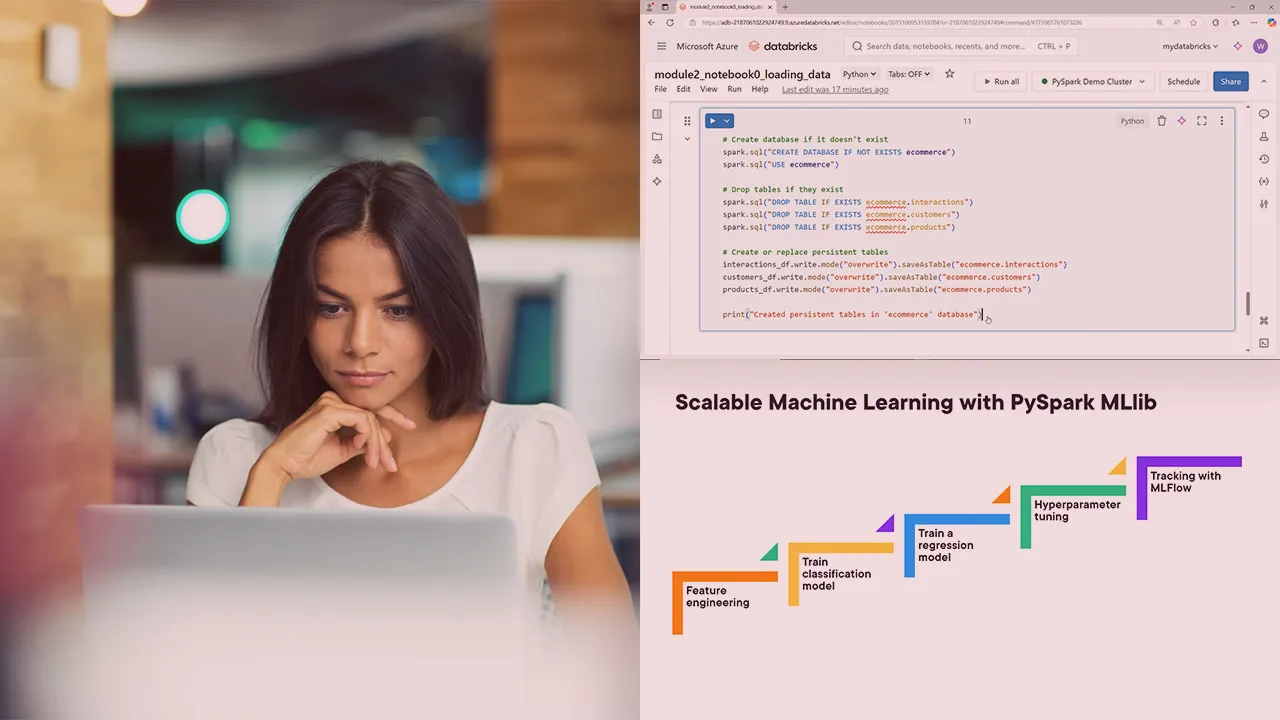
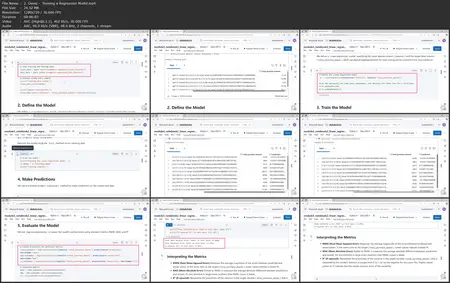
PySpark MLlib powers distributed machine learning. In this course, Scalable Machine Learning with PySpark MLlib, you’ll gain the ability to leverage Apache Spark’s distributed computing framework for your machine learning workloads. First, you’ll explore the fundamentals of Spark MLlib and the Spark ML Pipeline API, learning how it differs from single‐machine solutions.
Next, you’ll discover how to perform feature engineering and build classification/regression models that can handle big datasets efficiently.
Finally, you’ll learn how to tune hyperparameters and optimize performance so that your pipelines can run smoothly and quickly.
When you’re finished with this course, you’ll have the skills and knowledge of PySpark MLlib needed to implement and scale out your own machine learning solutions on large datasets.
Scalable Machine Learning with PySpark MLlib