Programming Generative AI

Programming Generative AI
ISBN: 0135381096 | .MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 18h 15m | 4.03 GB
Instructor: Jonathan Dinu
ISBN: 0135381096 | .MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 18h 15m | 4.03 GB
Instructor: Jonathan Dinu
From variational autoencoders to Stable Diffusion with PyTorch and Hugging Face.
Overview
Programming Generative AI is a hands-on tour of deep generative modeling, taking you from building simple feedforward neural networks in PyTorch all the way to working with large multimodal models capable of simultaneously understanding text and images. Along the way, you will learn how to train your own generative models from scratch to create an infinity of images, generate text with large language models similar to the ones that power applications like ChatGPT, write your own text-to-image pipeline to understand how prompt- based generative models actually work, and personalize large pretrained models like stable diffusion to generate images of novel subjects in unique visual styles (among other things).
Skill Level
Intermediate to advanced
Learn How To
- Train a variational autoencoder with PyTorch to learn a compressed latent space of images
- Generate and edit realistic human faces with unconditional diffusion models and SDEdit
- Use large language models such as GPT2 to generate text with Hugging Face Transformers
- Perform text-based semantic image search using multimodal models such as CLIP
- Program your own text-to-image pipeline to understand how prompt-based generative models such as Stable Diffusion actually work
- Properly evaluate generative models, both qualitatively and quantitatively
- Automatically caption images using pretrained foundation models
- Generate images in a specific visual style by efficiently fine-tuning Stable Diffusion with LoRA.
- Create personalized AI avatars by teaching pretrained diffusion models new subjects and concepts with Dreambooth.
- Guide the structure and composition of generated images using depth- and edge- conditioned ControlNets
- Perform near real-time inference with SDXL Turbo for frame-based video-to-video translation
Who Should Take This Course
- Engineers and developers interested in building generative AI systems and applications
- Data scientists interested in working with state-of-the-art deep learning models
- Students, researchers, and academics looking for an applied or hands-on resource to complement theoretical or conceptual knowledge they may have.
- Technical artists and creative coders who want to augment their creative practice
- Anyone interested in working with generative AI who does not know where or how to start
Course Requirements
- Comfortable programming in Python
- Knowledge of machine learning basics
- Familiarity with deep learning and neural networks will be helpful but is not required
Lesson 1: The What, Why, and How of Generative AI
Lesson 1 starts off with an introduction to what generative AI actually is, at least as it's relevant to this course, before moving into the specifics of deep generative modeling. It covers the plethora of possible multimodal models (in terms of input and output modalities) and how it is possible for algorithms to actually generate rich media seemingly out of thin air. The lesson wraps up with a bit of the formalization and theory of deep generative models, and the tradeoffs between the various types of generative modeling architectures.
Lesson 2: PyTorch for the Impatient
Lesson 2 begins with an introduction to PyTorch and deep learning frameworks in general. Jonathan shows you how the combination of automatic differentiation and transparent computation on GPUs have really enabled the current explosion of deep learning research. He also shows you how you can use PyTorch to implement and learn a linear regression model as a stepping stone to building much more complex neural networks. Finally, the lesson demonstrates how to combine all of the components that PyTorch provides to build a simple feedforward multi-layer perceptron.
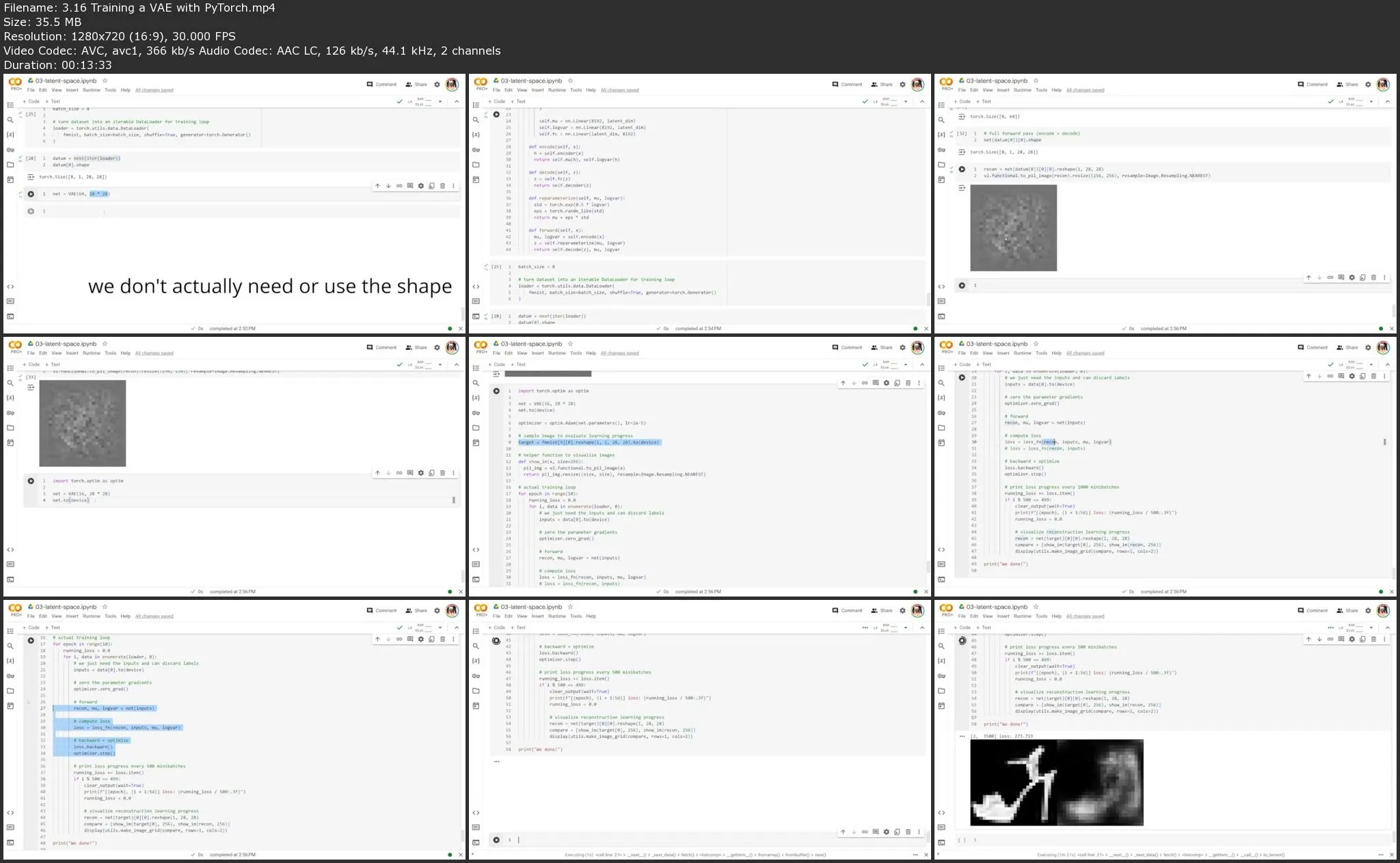
Lesson 3: Latent Space Rules Everything Around Me
Lesson 3 starts with a primer on how computer programs actually represent images as tensors of numbers. Jonathan covers the details of convolutional neural networks and the specific architectural features that enable computers “to see”. Next, you get your first taste of latent variable models by building and training a simple autoencoder to learn a compressed representation of input images. At the end of the lesson, you encounter your first proper generative model by adding probabilistic sampling to the autoencoder architecture to arrive at the variational autoencoder (VAE)—a key component in future generative models that we will encounter.
Lesson 4: Demystifying Diffusion
Lesson 4 begins with a conceptual introduction to diffusion models, a key component in current state of the art text-to-image systems such as Stable Diffusion. Lesson 4 is your first real introduction to the Hugging Face ecosystem of open-source libraries, where you will see how we can use the Diffusers library to generate images from random noise. The lesson then slowly peels back the layers on the library to deconstruct the diffusion process and show you the specifics of how a diffusion pipeline actually works. Finally, you learn how to leverage the unique affordances of a diffusion model’s iterative denoising process to interpolate between images, perform image-to-image translation, and even restore and enhance images.
Lesson 5: Generating and Encoding Text with Transformers
Just as Lesson 4 was all about images, Lesson 5 is all about text. It starts with a conceptual introduction to the natural language processing pipeline, as well as an introduction to probabilistic models of language. You then learn how you can convert text into a representation more readily understood by generative models and explore the broader utility of representing words as vectors. The lesson ends with a treatment of the transformer architecture, where you will see how you can use the Hugging Face Transformers library to perform inference with pre-trained large language models (LLMs) to generate text from scratch.
Lesson 6: Connecting Text and Images
Lesson 6 starts off with a conceptual introduction to multimodal models and the requisite components needed. You see how contrastive language image pre-training jointly learns a shared model of images and text, and learn how that shared latent space can be used to build a semantic image search engine. The lesson ends with a conceptual overview of latent diffusion models, before deconstructing a Stable Diffusion pipeline to see precisely how text-to-image systems can turn a user supplied prompt into a never-before-seen image.
Lesson 7: Post-Training Procedures for Diffusion Models
Lesson 7 is all about adapting and augmenting existing pre-trained multimodal models. It starts with the more mundane, but exceptionally important, task of evaluating generative models before moving on to methods and techniques for parameter efficient fine tuning. You then learn how to teach a pre-trained text-to-image model such as Stable Diffusion about new styles, subjects, and conditionings. The lesson finishes with techniques to make diffusion much more efficient to approach near real-time image generation.
Lesson 1 starts off with an introduction to what generative AI actually is, at least as it's relevant to this course, before moving into the specifics of deep generative modeling. It covers the plethora of possible multimodal models (in terms of input and output modalities) and how it is possible for algorithms to actually generate rich media seemingly out of thin air. The lesson wraps up with a bit of the formalization and theory of deep generative models, and the tradeoffs between the various types of generative modeling architectures.
Lesson 2: PyTorch for the Impatient
Lesson 2 begins with an introduction to PyTorch and deep learning frameworks in general. Jonathan shows you how the combination of automatic differentiation and transparent computation on GPUs have really enabled the current explosion of deep learning research. He also shows you how you can use PyTorch to implement and learn a linear regression model as a stepping stone to building much more complex neural networks. Finally, the lesson demonstrates how to combine all of the components that PyTorch provides to build a simple feedforward multi-layer perceptron.
Lesson 3: Latent Space Rules Everything Around Me
Lesson 3 starts with a primer on how computer programs actually represent images as tensors of numbers. Jonathan covers the details of convolutional neural networks and the specific architectural features that enable computers “to see”. Next, you get your first taste of latent variable models by building and training a simple autoencoder to learn a compressed representation of input images. At the end of the lesson, you encounter your first proper generative model by adding probabilistic sampling to the autoencoder architecture to arrive at the variational autoencoder (VAE)—a key component in future generative models that we will encounter.
Lesson 4: Demystifying Diffusion
Lesson 4 begins with a conceptual introduction to diffusion models, a key component in current state of the art text-to-image systems such as Stable Diffusion. Lesson 4 is your first real introduction to the Hugging Face ecosystem of open-source libraries, where you will see how we can use the Diffusers library to generate images from random noise. The lesson then slowly peels back the layers on the library to deconstruct the diffusion process and show you the specifics of how a diffusion pipeline actually works. Finally, you learn how to leverage the unique affordances of a diffusion model’s iterative denoising process to interpolate between images, perform image-to-image translation, and even restore and enhance images.
Lesson 5: Generating and Encoding Text with Transformers
Just as Lesson 4 was all about images, Lesson 5 is all about text. It starts with a conceptual introduction to the natural language processing pipeline, as well as an introduction to probabilistic models of language. You then learn how you can convert text into a representation more readily understood by generative models and explore the broader utility of representing words as vectors. The lesson ends with a treatment of the transformer architecture, where you will see how you can use the Hugging Face Transformers library to perform inference with pre-trained large language models (LLMs) to generate text from scratch.
Lesson 6: Connecting Text and Images
Lesson 6 starts off with a conceptual introduction to multimodal models and the requisite components needed. You see how contrastive language image pre-training jointly learns a shared model of images and text, and learn how that shared latent space can be used to build a semantic image search engine. The lesson ends with a conceptual overview of latent diffusion models, before deconstructing a Stable Diffusion pipeline to see precisely how text-to-image systems can turn a user supplied prompt into a never-before-seen image.
Lesson 7: Post-Training Procedures for Diffusion Models
Lesson 7 is all about adapting and augmenting existing pre-trained multimodal models. It starts with the more mundane, but exceptionally important, task of evaluating generative models before moving on to methods and techniques for parameter efficient fine tuning. You then learn how to teach a pre-trained text-to-image model such as Stable Diffusion about new styles, subjects, and conditionings. The lesson finishes with techniques to make diffusion much more efficient to approach near real-time image generation.
Programming Generative AI