Cloud Hadoop: Scaling Apache Spark

Cloud Hadoop: Scaling Apache Spark
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 3h 15m | 483 MB
Instructor: Lynn Langit
.MP4, AVC, 1280x720, 30 fps | English, AAC, 2 Ch | 3h 15m | 483 MB
Instructor: Lynn Langit
Apache Hadoop and Spark make it possible to generate genuine business insights from big data. The Amazon cloud is natural home for this powerful toolset, providing a variety of services for running large-scale data-processing workflows. Learn to implement your own Apache Hadoop and Spark workflows on AWS in this course with big data architect Lynn Langit.
Explore deployment options for production-scaled jobs using virtual machines with EC2, managed Spark clusters with EMR, or containers with EKS. Learn how to configure and manage Hadoop clusters and Spark jobs with Databricks, and use Python or the programming language of your choice to import data and execute jobs. Plus, learn how to use Spark libraries for machine learning, genomics, and streaming. Each lesson helps you understand which deployment option is best for your workload.
Learning objectives
- File systems for Hadoop and Spark
- Working with Databricks
- Loading data into tables
- Setting up Hadoop and Spark clusters on the cloud
- Running Spark jobs
- Importing and exporting Python notebooks
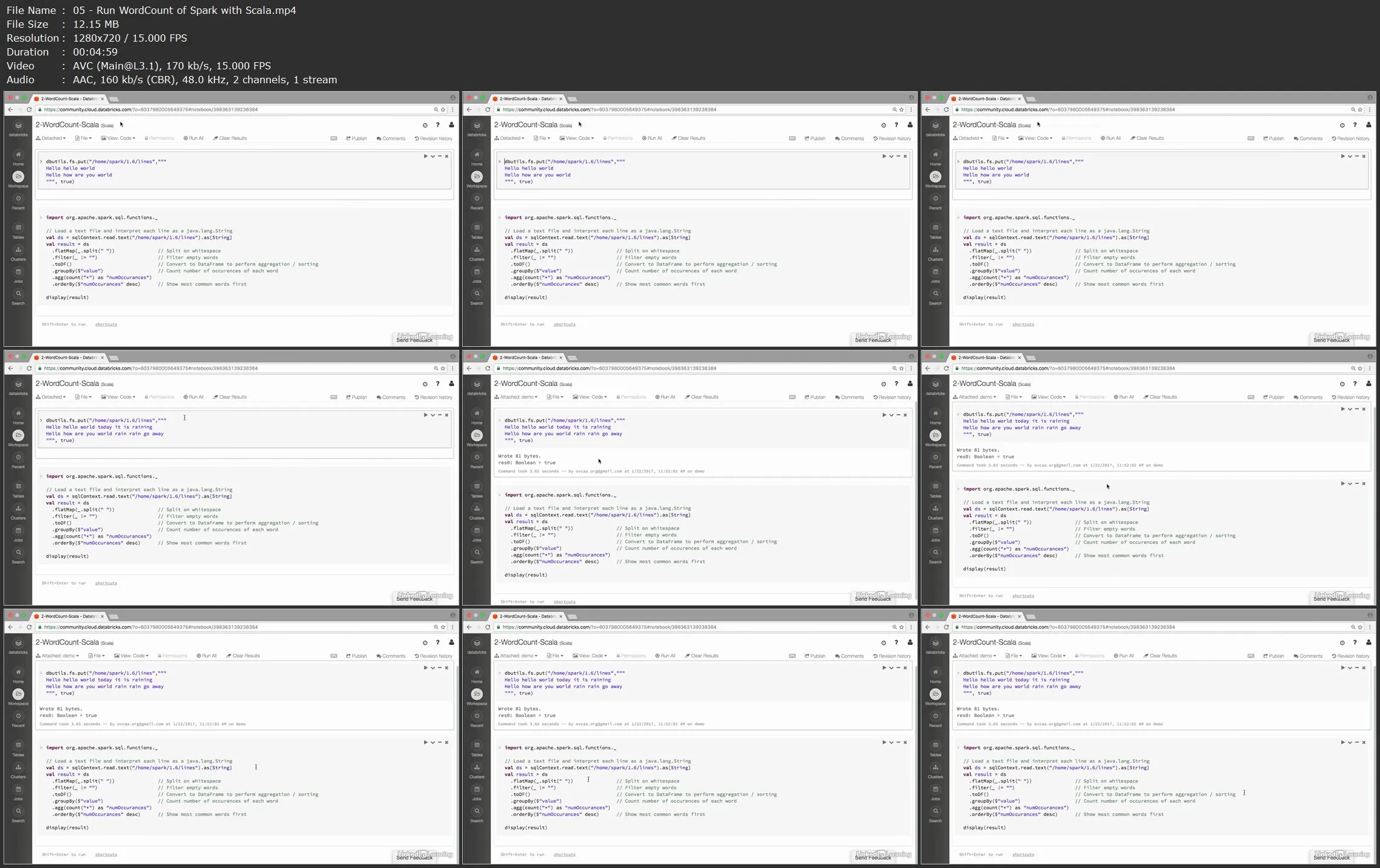
- Executing Spark jobs in Databricks using Python and Scala
- Importing data into Spark clusters
- Coding and executing Spark transformations and actions
- Data caching
- Spark libraries: Spark SQL, SparkR, Spark ML, and more
- Spark streaming
- Scaling Spark with AWS and GCP
Cloud Hadoop: Scaling Apache Spark