

Timeplus Enterprise 2.5.11 (Linux/macOS)
Timeplus Enterprise 2.5.11 (Linux/macOS) | 356.2/410.8 Mb
Collect, Transform, Route, and Alert on Real-Time Data. Timeplus simplifies stateful stream processing and analytics with a single-binary engine. Reduce time, complexity, and cost by using SQL to build real-time applications, data pipelines, and dashboards at the edge or cloud.
Collection
With built-in External Streams and External Tables, Timeplus can natively collect real-time data from, or send data to, Kafka, Redpanda, ClickHouse, or another Timeplus instance, without any data duplication. Timeplus also supports a wide range of data sources through sink/source connectors. Users can push data from files (CSV/TSV), via native SDKs in Java, Go, or Python, JDBC/ODBC, Websockets, or REST APIs.
Transformation
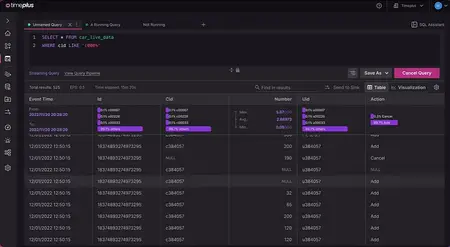
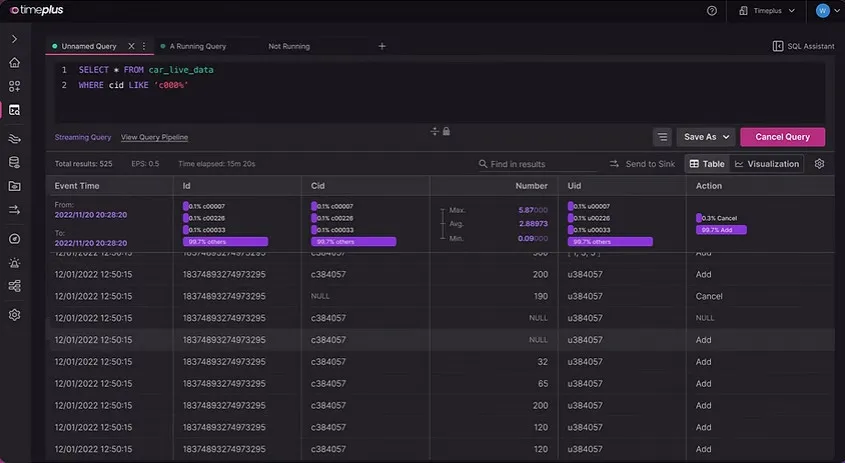
With a powerful streaming SQL console, users can leverage their preferred query language to create Streams, Views, and incremental Materialized Views. This enables them to transform, roll up, join, correlate, enrich, aggregate, and downsample real-time data, generating meaningful outputs for real-time alerting, analytics, or any downstream systems.
Routing
Timeplus allows data to be routed to different sinks based on SQL-based criteria and provides a data lineage view of all derived streams in its console. A single data result can generate multiple outputs for various scenarios and systems, such as analytics, alerting, compliance, etc., without any vendor lock-in.
Analytics and Alerting
Powered by SSE (Server-Sent Events), Timeplus supports push-based, low-latency dashboards to visualize real-time insights through data pipelines or ad-hoc queries. Additionally, users can easily build observability dashboards using Grafana plugins. SQL-based rules can be used to trigger or resolve alerts in systems such as PagerDuty, Slack, and other downstream platforms.
Unified streaming and historical data processing
Timeplus streams offer high performance, resiliency, and seamless querying by using an internal Write Ahead Log (WAL) and Historical Store. The WAL ensures ultra-fast inserts and updates, while the Historical Store, optimized for various query types, handles efficient historical queries.
This architecture transparently serves data to users based on query type from both, often eliminating the need for Apache Kafka as a commit log or a separate downstream database, streamlining your data infrastructure.
Home Page - https://www.timeplus.com/